


What machine learning has to say about voting eligibility
Voting should be more accessible. Ensemble models show us why.

There’s a folk theory that anyone that isn’t well informed shouldn’t vote, or even shouldn’t have the right to vote.
This line of thinking, whose intuitive appeal is basically that a person shouldn’t do something that affects everyone else without knowing how, has been frequently exercised by right-wing pundits in light of the passage of Georgia’s new election law.

But this line of thinking is wrong, and statistical modeling shows us why. Including more voters makes our elections more accurate (in the sense of picking the better candidate for a wider range of voters) and including more uninformed voters does not make elections less accurate. This case can be made persuasively by drawing an analogy between elections and predictions, by considering a vote as a prediction of which candidate will be the better officeholder from the perspective of the voter.
Machine learning is quite concerned with how to make the most accurate predictions, and we can use results from that field to inform how we think about uninformed voters. One way to make more accurate predictions is to build not just one model but many, and then to average their predictions together. These groups of models, which are called “ensembles”, are generally much more effective than any single model.
The reason that ensembles work better than single models is the same reason you’d be well advised to have different perspectives among your advisors when making a decision, and stocks with different sensitivities to the economy in your portfolio. Rarely will one advisor have all the relevant perspectives, and never will one stock respond positively to all different economic circumstances.
This type of decision-making — averaging several predictions together — is called “bagging” in the machine learning literature, and it has a direct analogy to elections by popular vote. Think of each voter as a model, capturing data through their experiences and making a prediction about the candidates.1
We might ask which findings from research on bagging are relevant to voting. One strange finding is that you want your individual models to be “weak” rather than “strong”. You want their accuracy to be better than a coin flip, but not necessarily by much. Why? The same reason that you wouldn’t want to have a team of advisors that all told you the same thing (if they do, you only needed one advisor to begin with).
Ideally the predictions that you average together will be as uncorrelated as possible. And to make them uncorrelated, you must ensure that they are not all based on exactly the same data, or produced from the data in the same way. ML practitioners accomplish this by artificially limiting the amount of data that feeds into any single prediction; this actually makes the individual predictions worse, but improves the collective prediction.
This finding has an important implication for the folk theory that only more informed people should vote. Even if you could implement the theory at its logical conclusion, and somehow limit voting to a super-elite cadre of voters that were selected based on their familiarity with all the relevant issues, you would be ill-served to do so, as this would not be the optimal way to hold elections. The risk that they would all be wrong in the same way would be too high.
This finding also gives support to the way popular votes work in practice: each voter typically cares about a small set of issues; one voter will focus on climate change and environmental policy; another on economic stimulus and tax policy; yet another on foreign relationships and global trade.
But the question raised by these pundits goes further, and asks about the impact of “uninformed voters” who presumably aren’t focused on any issues. How do we define “uninformed” here, though? The most common framework is the “low-information voter”, coined by political scientist Samuel Popkin, who latch onto simple things like whether or not the candidate eats at McDonald’s to evaluate candidates (Bill Clinton did, and voters liked that). But formal mathematical definitions are hard to come by in the literature; the only definition that I can defend is that “uninformed” voters make utterly random choices with respect to the candidates. If their choices were anything but random, we’d be forced into making a paternalistic judgment about the source of their preferences.
Using this definition of an uninformed voter, we can model the question of how totally random voters impact elections. You may already intuit the result, which is that the random, uninformed votes simply cancel each other out. This simulation tallies up the results of an election with a thousand experts, defined as voters who collectively vote for the candidate that would be better for their interests about 60% of the time, along with between one and a thousand uninformed voters, who vote randomly. As the plot shows, the vote margin (the difference between votes between two candidates) has no tendency to increase or decrease, or even to become more uncertain, as the number of uninformed voters goes up.
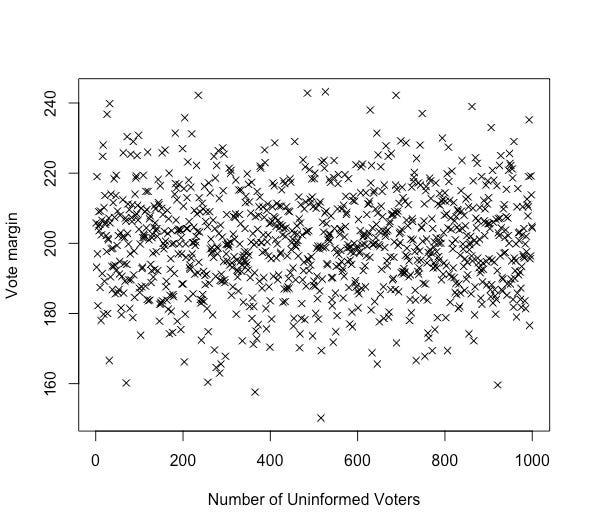
If your position is that there should be fewer, “better qualified” voters, you have to either (a) contend with the fact that uninformed voters’ votes are random, will simply cancel each other out, and in total will have no effect, or (b) make the argument that while these uninformed voters do not make random choices, the source of their predisposition is categorically wrong, somehow. I certainly would not leave it to anyone to determine which reasons are valid or invalid when casting a vote
I also wouldn’t trust any policymaker to go beyond the simplest categories when creating criteria for who can vote or not. The risk, from a social, if not partisan, view, is that the categories for who can vote or not will correlate with some unique perspective. It seems inevitable that any but the crudest, most obviously equitable restrictions would happen to fall more heavily on one group vs. another. And if they do, isn’t that some indication that this group is different in some important ways from the rest of the population? And if they are, wouldn’t this indicate that their predictions will be different, and important to include? If restrictions happen to make it more difficult for rural voters, Black voters, low-income voters, or whomever, our system for choosing the best candidate for the country will not be as accurate as it could be.
Thank you to Marshall Moutenot who graciously helped me edit this.
ML practitioners may note another analogy: Stacking is the same mechanism as representative democracy; the first model is an election resulting in representatives, which feed into a “stacked” model, the votes among the representatives themselves.