The business of statistics
Model-first companies

Two posts ago, I went through the business of Gradient at the level of a rough sketch. In this one, I’ll talk about the kinds of businesses I’ve become (a bit) obsessed with. These kinds of businesses are built around a core statistical model that delivers critical intelligence to the client.
There is, frankly, a profusion of companies in data/ML. Matt Turck at First Mark Capital publishes a landscape of data/ML focused companies that is much more comprehensive than anything I will (or want to) attempt here.
In general, I see three major themes:
Better data. This could mean any of companies that go out and get proprietary data (like Second Measure or Planet), companies that help you store your data (e.g. Snowflake or Databricks), companies that help you keep track of transformations like Tecton, companies that help you track your data pipelines (Monte Carlo), and so on
Tools to build models. C3 AI, again Snowflake and Databricks, Mode Analytics, Domino Data Lab, etc. I would even include companies like Tableau and Plotly in this bucket because visualizations are models in-and-of-themselves. Hugging Face and Monkey Learn in NLP. These companies typically help analysts with off-the-shelf components for preprocessing and model development.
Vertical integration of the model to provide a better product. Lemonade in insurance, Stitch Fix in apparel, Opendoor in real estate etc.
The kinds of opportunities and companies that I’m interested in are areas where the model is the product being sold. In contrast to the “better data” category, these companies may not have any kind of data advantage or proprietary data. In contrast to the “tools” category, these companies don’t help you build a custom model, they provide the model to you. And in contrast to the “better product” category, the model isn’t a component of the product, the model is the product.
What kinds of companies would these be? The canonical example would be Optimizely, or its close cousin Visual Web Optimizer. These companies help you run A/B tests on landing pages, website copy, etc. They have essentially commercialized the beta-binomial model.
A new company that I am watching closely is Viable. They apply state-of-the-art natural language models to your customer reviews. They don’t bring the data — you do. You don’t build the model — they serve the results to you. They have commercialized (a variant of) GPT-3.
Why am I interested in these companies?
Well, the primary answer is that it is something that I’m personally interested in. I love building statistical models. If I sound like the world’s most boring person, consider that you’re reading that person’s blog! I kid. But seriously, I love building these little models of the world, getting them to work, and finding out interesting things.
Putting my MBA hat on, though, I think there are a few good business reasons to be interested in these kinds of companies. The first is that it is a highly balkanized space: most “model building” activity happens in siloed teams buried within organizations, and quite often there are disconnects between what management needs and what analytics / data science teams are doing (to put it mildly). This is an opportunity to build a better experience.
The second reason is that expanding a model’s input data across companies can improve the performance for any given company. In building Recast, we often learn things when running our model for one company that we then apply for every other customer we have. These kinds of learnings simply don’t exist inside of a single company’s data science org.
Finally, if it’s an important-enough problem and a good-enough (and differentiated-enough) solution, you can create very high switching costs for your customers, leading to high loyalty and high LTV.
Why would these companies exist?
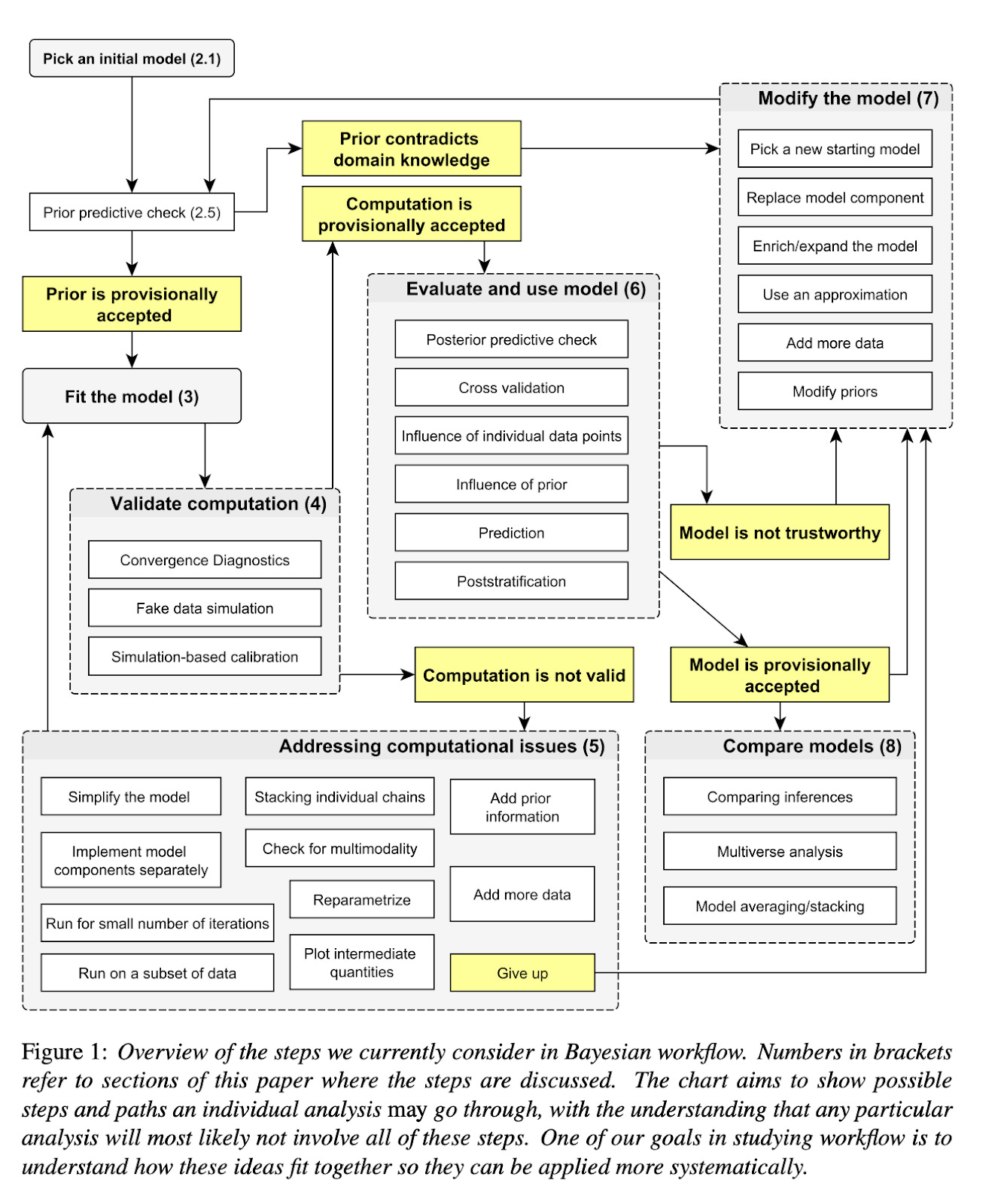
Good models are extraordinarily hard to build. Primarily, I know this from first-hand experience building models for clients. Statistical and ML models are designed objects; they are built to produce specific inferences with constraints around data shape, size, missingness; model priors and complexity; and compute time and space needs. For an illustration of the steps involved in building a good statistical model the right way, please take a peek at this 68-page manual on a Bayesian workflow (a flowchart is shown below). The manual touches on things like divergent transitions and multimodality / nonidentifiability, but knowing how to address those issues is expertise built on painstaking efforts building models and using insider know-how that’s (for the moment at least) poorly documented and even understood.
And besides that, probably the most important elements of building the model, like understanding the response distribution, the structure of the input data, the data generating processes under consideration, is yet another set of know-how that takes years of practice in applied settings to build.Nascent data primitives (e.g. customer reviews, transaction tables, marketing spend) from the sheer volume of data and emerging platforms make it easier to build models that have a large market. For example, every company running on Shopify has the same backend. These data primitives mean that it’s possible to build a model that assumes a given input structure and to have it be immediately applicable to a wide range of companies
If you put 1 and 2 together, you get one of three possible outcomes:
Missed opportunity: companies don’t build these models at all. Instead of building a media mix model, companies will rely exclusively on their last-touch attribution system and post-checkout surveys, even knowing that they are biased towards lower-funnel channels and under-credit top-of-funnel channels. Instead of calibrating their cost per acquisition (CPA) targets on a per-channel basis using a customer lifetime value (CLV) model, companies will use a single number, knowing that they are being too conservative in some channels and too aggressive in others.
Poor approximations: companies build these models, but do so poorly. This can happen for a mix of two reasons: the first is the pressure to move through a backlog quickly combined with the fact that the process of building a truly performant, complex model can take orders of magnitude longer than stakeholders might expect. The second is that it’s really easy to build a bad model. A common failure path is to interpret your results as representing a causal relationship when building a regression (I’ve touched on that here and here). Another (more esoteric) failure path is to throw away the structure of ordinal predictors, which are everywhere (like education, or Likert-scale survey responses). If your predictor is from “strongly disagree” to “strongly agree” and you code this as 1-5, or as five separate binary variables, you’re either assuming more information than the data is giving you, or less. There are ways to do this right, but they’re complex (and yes, they do matter)
Wasted energy: companies A and B (and C, D, and so on) both invest the time and energy to build these models. This can cost several millions of dollars in labor, many person-years of bandwidth, on top of huge opportunity cost.
Data scientists within firms should be working on problems for which at least one of the following is true:
The input data is unique to them (on a qualitative basis)
The problem is unique to them
The model is core to their value proposition to consumers (e.g. Opendoor shouldn’t be using the same home valuation model as everyone else; that would be lunacy)
For everything else, it’s a better business decision to outsource it. This shouldn’t be controversial; it’s accepted business wisdom to focus on being best-in-breed for the things that make you unique. No one is racking their own servers these days: just use AWS. No one is building their own custom CRM: just use Salesforce (or whichever CRM you like).
Why now?
I already mentioned one reason, which was that shared data primitives are becoming more common. Another reason is that you simply couldn’t build most interesting and complex statistical/ML models until sometime within about 2012-2015. This is when packages like Stan (2012), PyMC3 (2013), TensorFlow/Keras (2015), MXNet (2015), PyTorch (2015) came out. The No-U-Turn Sampler paper came out in 2011. The paper that Stan uses for Automatic Differentiation Variational Inference came out in 2015. Most of the hard conceptual work on deep learning had been done well before computers were powerful enough to take advantage of them, but it’s telling that this XKCD comic came out in 2014, which illustrates the state of deep learning and computer vision at that time. This task is trivial today.
Before 2012-2015, there simply was no wasted opportunity, wasted energy, nor poor approximations, because — for most businesses — there was no way to build most of the models that would be transformative for a business.
Recast is a model with 30-40k parameters (don’t worry, it has far fewer effective parameters). That’s a gob-smackingly large number of things for a computer to estimate (at least when you’re talking statistics; it’s several orders of magnitude fewer parameters than most deep learning models).