No, ML is not "just statistics"
No, ML is not "just statistics"
Debugging an oft-repeated bad take

If you follow enough data science folks on the internet, eventually you’ll come across a take that essentially goes like this:

And even folks that you might expect to be on the other side of this debate, seeing as how they are associated with major AI things like self-driving cars (putting aside how well Tesla’s “Full Self Driving” performs in practice — as you should know by now I’m quite skeptical of self-driving cars in general), and would therefore perhaps feel some motivation to stress that AI (which is just an alias for ML) is a separate discipline from statistics, pile on:


In both statistics and machine learning you generally have:
A function that produces a loss value
This function is usually a combination of three things: data, both of predictors and of outputs; the component that produces the prediction for each set of predictors; and the component that judges how accurate the prediction was (e.g. a likelihood or loss function)Free parameters that go into the function
In a linear regression these would be the values of the intercept and coefficients. In a decision tree this might be a list of all the splits in the data. In a neural network this will be the values for the weights and biases for each node.
In both statistics and machine learning you are generally trying to optimize (2) to improve the “loss value” in (1).
Let’s pause here: can this be what the “ML is just statistics” folks mean? That since both disciplines share this overall structure (change parameters to improve a loss function) that they are equivalent? It can’t be; if this were so, then while it would be the case that “ML is just statistics”, it would also be the case that “ML and statistics are both just optimization”. Which, sure, maybe, but how helpful is that?
I think what a lot of people mean when they say that “ML is just statistics” is that many of the loss functions are the same. And this is true! What ML folks call “softmax”, statisticians call “multinomial logistic regression”. I don’t even know what ML folks call plain old logistic regression, maybe “binary crossentropy loss” or some such. So this is true. It’s also true that a single layer neural network with whatever name ML people use for logistic regression just is a logistic regression.
So, in this very narrow sense, “ML is just statistics”. If you find yourself ever using a single layer neural network to do binary classification in tensorflow, yes, you could just do glm(target ~ predictors, family = binomial) in R, and it would be easier.
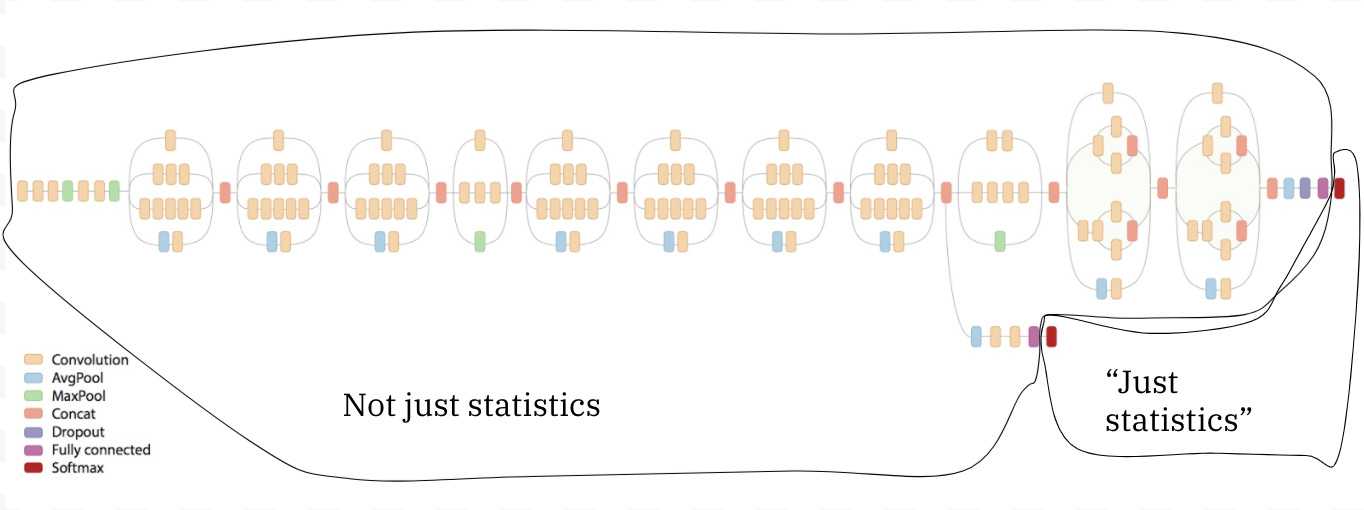
What lies beyond this very narrow sense, though, is what makes ML interesting. To illustrate with an example, let’s say you’re using a neural network to decide whether or not an image contains a cancerous tumor. It’s absolutely true that the last layer of the neural network will be a linear model and have the same functional form as a logistic regression. But what about what goes into that last layer?
In your multilayer neural network, the stuff going into the last layer will be the product of multiple layers that make nonlinear transformations, and that hopefully represent interesting features of the data. This post from Google shows how progressive layers represent ever more complex features of an image.

In fact, one way to think about neural networks is that almost everything they’re doing is feature engineering, and they (hopefully) do such a good job of representation that the final task of prediction can be done with a dead-simple linear model.
Again from Google, we can take this image of the Inception-v4 architecture and annotate where you can meaningfully use the tools of statistics to understand what’s going on. Just two nodes — the two output nodes — qualify. Everything else is the part of the network that is doing feature engineering, and in which no concept from statistics would be helpful in understanding what’s going on.